Introducción a los Ficheros
Introdución os ficheiros
Na programación adoitan usarse variables para almacenar información que queremos tratar durante a execución: os datos de entrada, resultados e valores intermedios Con todo, a información almacenada nas variables é volátil, desaparecendo cando remata a execución do programa. Cando queremos almacenar de xeito permanente, fálase de persistencia, sendo dúas as formas máis habituais de facelo:
-
Organizado a información nun ou varios ficheiros nun sistema de almacenamento persistente
-
Facendo uso das facilidades que nos permiten as bases de datos Neste capítulo introduciremos a primeira das opcións; e para iso, comezaremos abordando a súa definición desde o punto de vista de máis baixo nivel:
-
Un ficheiro é un conxunto de bits almacenado nun dispositivo accesible a través dunha ruta (pathname) que o identifica.
Basicamente, unha secuencia de 1s e 0s que son almacenados fóra da memoria volátil do equipo (nun disco duro ou nun DVD, por exemplo). Desde un nivel máis alto, e para o que nos interesa desde o punto de vista da programación, esta é a información que debemos ter en conta.
Tipos de ficheiros
E posible facer moitas clasificacións, que iremos detallando a continuación.
Segundo a súa estrutura de almacenamento e contido
Podemos atopar coma tipos básicos de ficheiros os de texto plano e os binarios.
Os de texto plano almacenan secuencias de caracteres correspondentes a unha codificación determinada (ASCII, Unicode, EBCDIC, etc.). Son lexibles mediante un software de edición de texto coma o Bloc de Notas de Windows ou os editores Vi ou nano de Linux.
Exemplos:
- os ficheiros de texto con extensión .txt
- os .csv de valores separados por comas
- os .htm y .html correspondentes a páxinas web
- os de linguaxes de marcas .xml ou .rss.
O sistema de codificación de caracteres máis popular é o código ASCII (American Standard Code for Information Interchange, código estándar estadounidense para intercambio de información), que define 256 caracteres distintos (todas as combinacións de 8 bits,dous elevado a 8 posibilidades). Algúns deles, chamados caracteres de control, encárganse de definir accións coma o borrado, o salto de liña ou o tabulador e non representan símbolos concretos. Podes consultar na wikipedia máis información.
Os binarios conteñen información codificada en binario para o seu procesamento por parte de aplicacións. O seu contido resulta ilexible nun editor de texto. Exemplos: executables (.exe) documentos de aplicacións (.pdf, .docx, .xlsx, .pptx) ficheiros de imaxe, audio ou vídeo (.jpg, .gif, .mp3, .avi, .mkv) librerías de sistema (.dll).
Por organización interna
Cando se utilizan ficheiros de texto plano para almacenar información pódense clasificar conforme a súa ‘‘organización interna’’ en secuenciais, de acceso directo ou aleatorio, ou indexados. Nos secuenciais a información escríbese en posicións fisicamente contiguas. Para acceder a un dato hai que recorrer todos os anteriores. Exemplo de ficheiro secuencial con información sobre clientes: 00789521T#Alba#Blanco#González#613524647$11111111H#Xosé Ramon#García#Pemán#613423824$38546998X#Xurxo#Cazás#Otero#666332245$09653801B#Antón#Resines#Pardo#619335241%
Por cada contacto estruturouse a información en cinco datos independentes: NIF, nome, primeiro apelido, segundo apelido e número de teléfono. Neste caso o programador decidiu utilizar o grade (#) como separador de datos, o dólar ($) como separador de contactos e o tanto por cento (%) coma marca de fin de ficheiro. Nos de acceso directo ou aleatorio cada liña de contido organízase cuns tamaños fixos de dato. Pódese acceder directamente ó principio de cada liña.
Nesta ocasión cada contacto ocupa unha liña do ficheiro (o final de cada unha o sistema operativo incluirá un ou dos caracteres de salto de liña invisibles para o usuario), e cada dato utiliza un número de caracteres fixo, aínda que non o ocupe totalmente (no exemplo reservanse 15 caracteres para o nome, aínda que no caso de Alba só se utilicen catro).
Finalmente, nos indexados, xeralmente nun ficheiro de acceso aleatorio a información almacénase na orde en que se da de alta. Aínda que se conseguira introducir a información de acordo a algún criterio de ordenación concreto, nalgunhas ocasións é útil poder ordenala por varios criterios distintos. No exemplo anterior é posible que necesitemos un listado de clientes ordenado por NIF e outro polo apelido. Para dar solución a este problema creouse a organización indexada, que consiste na existencia de un ou varios arquivos adxuntos que ordenan o dato (chamado clave) polo que se desexa ordenar o ficheiro e o relacionan coa localización da liña correspondente.
Por tipos de soporte de almacenamento
De “acordo á organización física dos datos”, diferenciamos entre dous tipos de soportes Nos secuenciais para acceder a un dato hai que recorrer todo o contido do soporte previo ó devandito dato (por exemplo, as cintas magnéticas). Nos direccionables pódese acceder directamente a un dato sen ter que recorrer todos os anteriores (por exemplo un disco duro). Nun soporte direccionable pódese implementar un acceso secuencial, directo ou indexado, mentres que nun soporte secuencial só se poderá implementar un acceso secuencial.
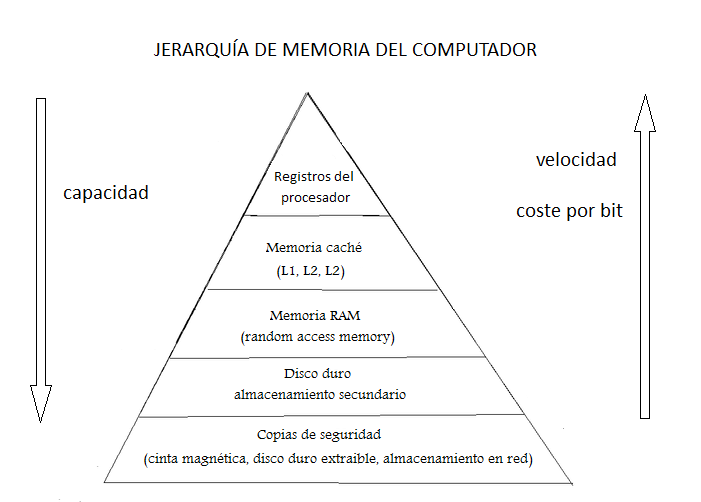
Por xerarquía de memorias
Os ficheiros adoitan almacenarse en diferentes memorias, tendo en conta que hai que atopar un compromiso entre a velocidade de acceso desexada, a capacidade requirida e o custo por bit.
E/S con fluxos
En Java defínese a abstracción de stream (fluxo) para tratar a comunicación de información entre o programa e o exterior. Entre unha fonte e un destino flúe unha secuencia de datos: os fluxos, que actúan coma interfaz co dispositivo ou clase asociada. Así permiten:
- Operación independente do tipo de datos e do dispositivo
- Maior flexibilidade (redirección, combinación, …)
- Diversidade de dispositivos (ficheiro, pantallas, teclado, rede, …)
- Diversidade de formas de comunicación (con modo de acceso secuencial ou aleatorio, e información intercambiada que pode ser binaria, caracteres ou liñas)
Analoxía entre UNIX e Java
Hai unha certa analoxía entre o funcionamento en Unix e en Java:
| Unix | Java | |
|---|---|---|
| Entrada estándar | Habitualmente teclado | System.in |
| Saída estándar | Habitualmente a consola | System.out |
| Saída de erro | Habitualmente a consola | System.err |
En Java accedese á E/S estándar a través dos campos estáticos da clase java.lang.System indicados.
Utilización dos fluxos
Lectura
- Abrir un fluxo a unha fonte de datos (creación do obxecto stream)
- Teclado
- Fichero
- Socket remoto
- Mentres existan datos dispoñibles
- Ler datos
- Cerrar o fluxo (método close)
Escritura
- Abrir un fluxo a unha fonte de datos (creación do obxecto stream)
- Pantalla
- Ficheiro
- Socket local
- Mentres existan datos dispoñibles
- Escribir datos
- Cerrar o fluxo (método close) A ter en conta: o sistema xa se encarga de abrir e pechar os fluxos estándar un fallo en calquera punto produce a excepción IOException Para o que estamos a tratar, serán de interese os File streams para escribir e ler datos en ficheiros
Exemplo de entrada de texto desde un ficheiro
try {
BufferedReader reader = new BufferedReader(new FileReader(“nomeficheiro"));
String linea = reader.readLine();
while(linea != null) {
// procesar o texto da liña
linea = reader.readLine();
}
reader.close();
}
catch(FileNotFoundException e) {
// non se atopou o ficheiro
}
catch(IOException e) {
// algo foi mal ó ler ou pechar o ficheiro
}
De xeito xeral, pódese comprender o funcionamento do código… pero para mellorar o seu entendemento, explicaremos que son as excepcións e como facer uso das mesmas.
Uso de finally:
import java.io.*;
public class SimpleExceptionHandling {
public static void main(String[] args) {
FileInputStream fileInputStream = null;
try {
fileInputStream = new FileInputStream("C:\\UnFicheiroTemporal");
} catch (FileNotFoundException e) {
System.out.println("Aconteceu a excepción :: " + e.getMessage());
System.out.println("Necesitamos pechar FileStream!");
} finally {
System.out.println("Afortunadamente pecharase neste bloque");
try {
if (fileInputStream != null) {
fileInputStream.close();
}
} catch (IOException e) {
}
}
}
}
try-with-resources
Mecanismo que automaticamente pecha recursos (pode ser máis de un) cando se acabou o seu traballo con eles. Por exemplo:
private static void printFile() throws IOException {
try(FileInputStream input = new FileInputStream("ficheiro.txt")) {
int data = input.read();
while(data != -1){
System.out.print((char) data);
data = input.read();
}
}
}
Neste exemplo ábrese un FileInputStream dentro dun bloque try-with-resources, lee datos do FileInputStream, e pechao automaticamente cando a execución sae do bloque. Isto último e posible porque FileInputStream implementa a interface java.lang.AutoCloseable
Exercicio 1
Partindo do seguinte código, simplificalo co uso de try-with-resources.
Scanner scanner = null;
try {
scanner = new Scanner(new File("test.txt"));
while (scanner.hasNext()) {
System.out.println(scanner.nextLine());
}
} catch (FileNotFoundException e) {
e.printStackTrace();
} finally {
if (scanner != null) {
scanner.close();
}
}